ggplot(pop_data, aes(age, pcnt2, fill = sex)) +
geom_col(show.legend = FALSE) +
coord_flip(ylim = c(-.08, .08)) +
labs(title = "Population by Age and Gender:
{floor(frame_time/5)*5}",
x = "Age", y = "Percent of Population") +
scale_fill_manual(
values = c("hotpink3", "dodgerblue3")) +
scale_y_continuous(
breaks = seq(-.08, .08, .02),
labels = abs(seq(-8, 8, 2)) |> paste0("%")) +
annotate("text", label = "Female", size = 8,
color = "hotpink3", x = 20, y = .05) +
annotate("text", label = "Male", size = 8,
color = "dodgerblue3", x = 20, y = -.05) +
gganimate::transition_time(year)Data Simulation and Code Review
Plots!

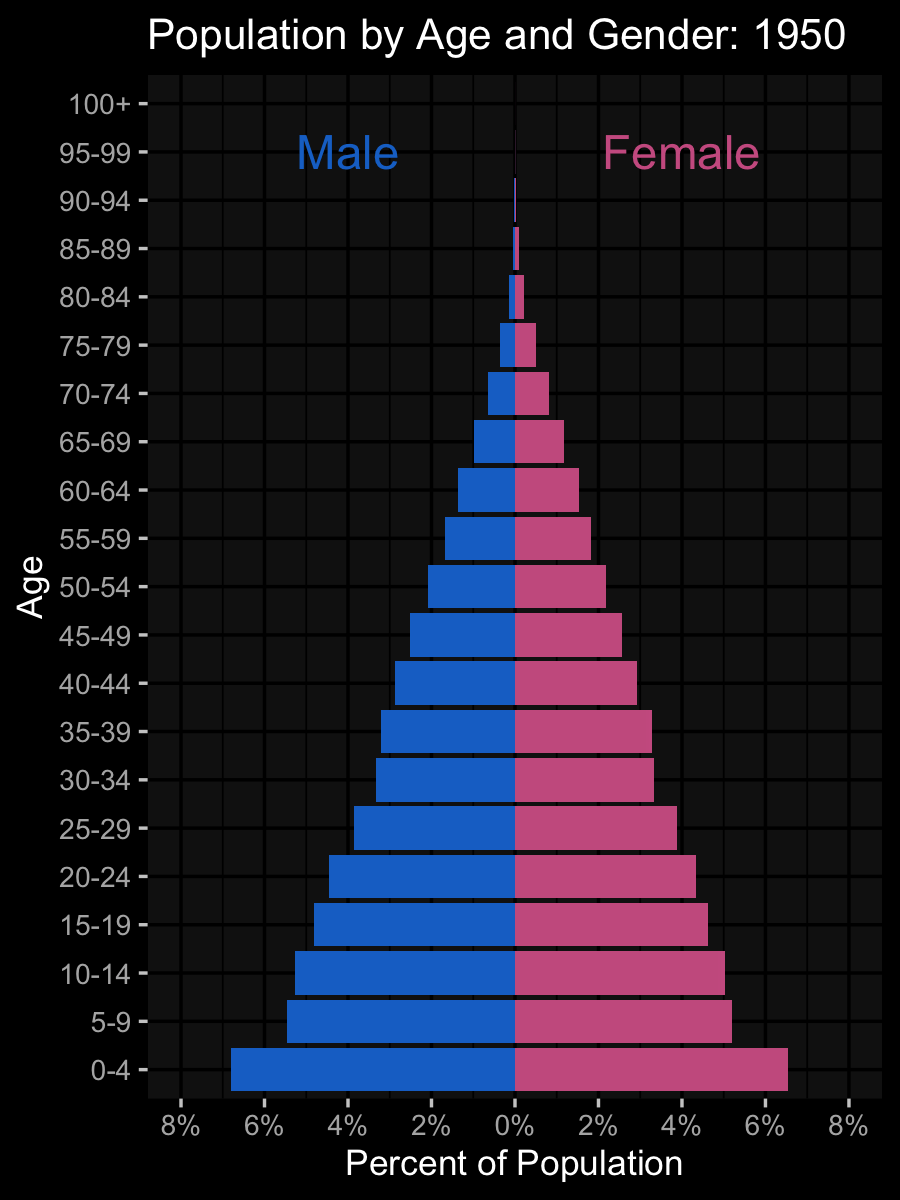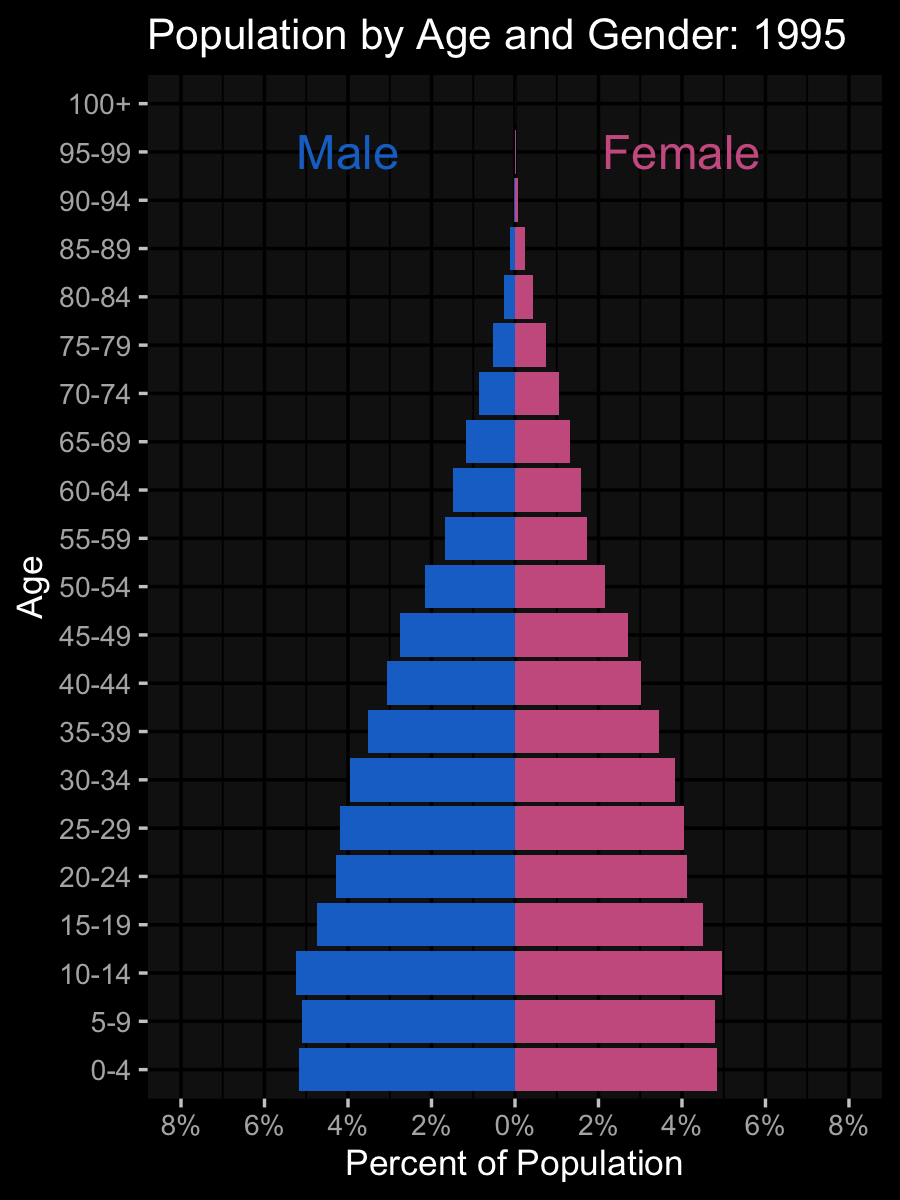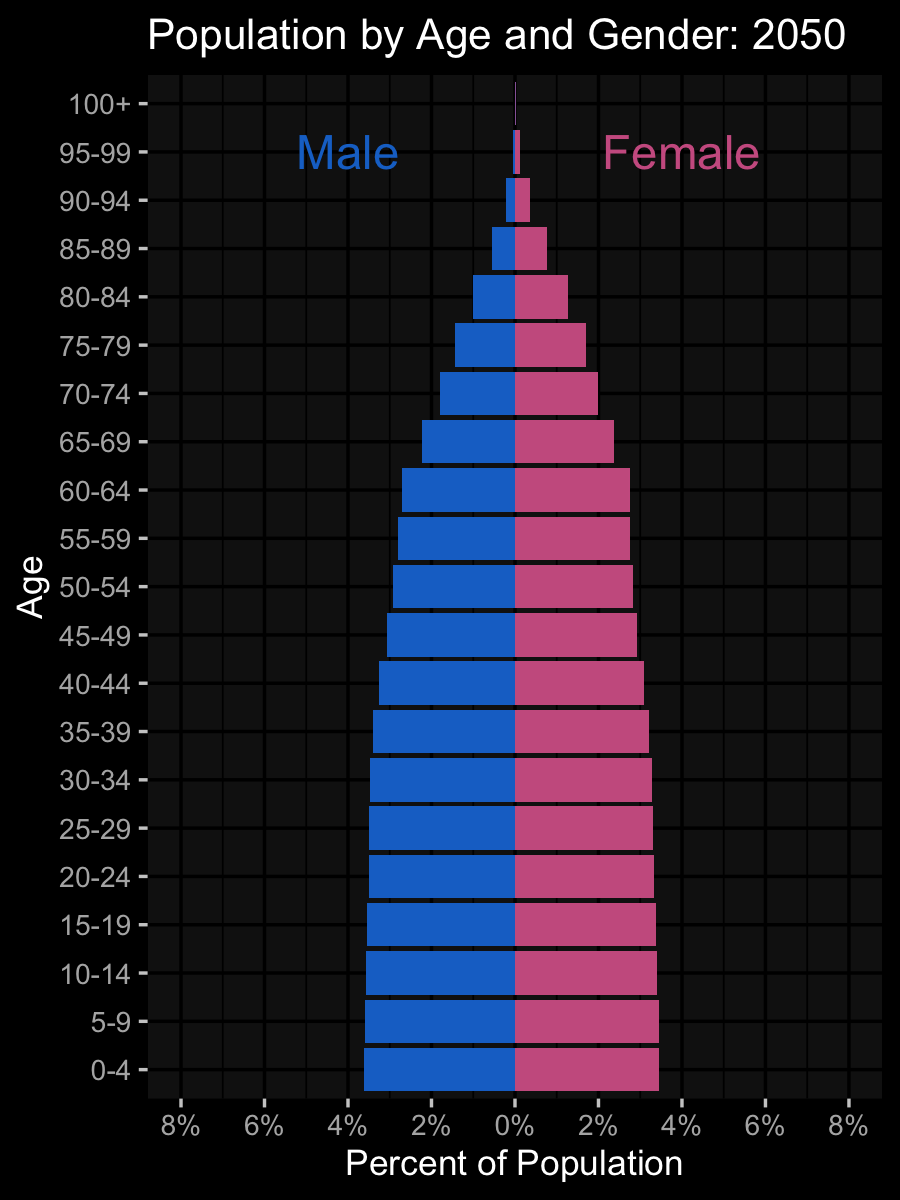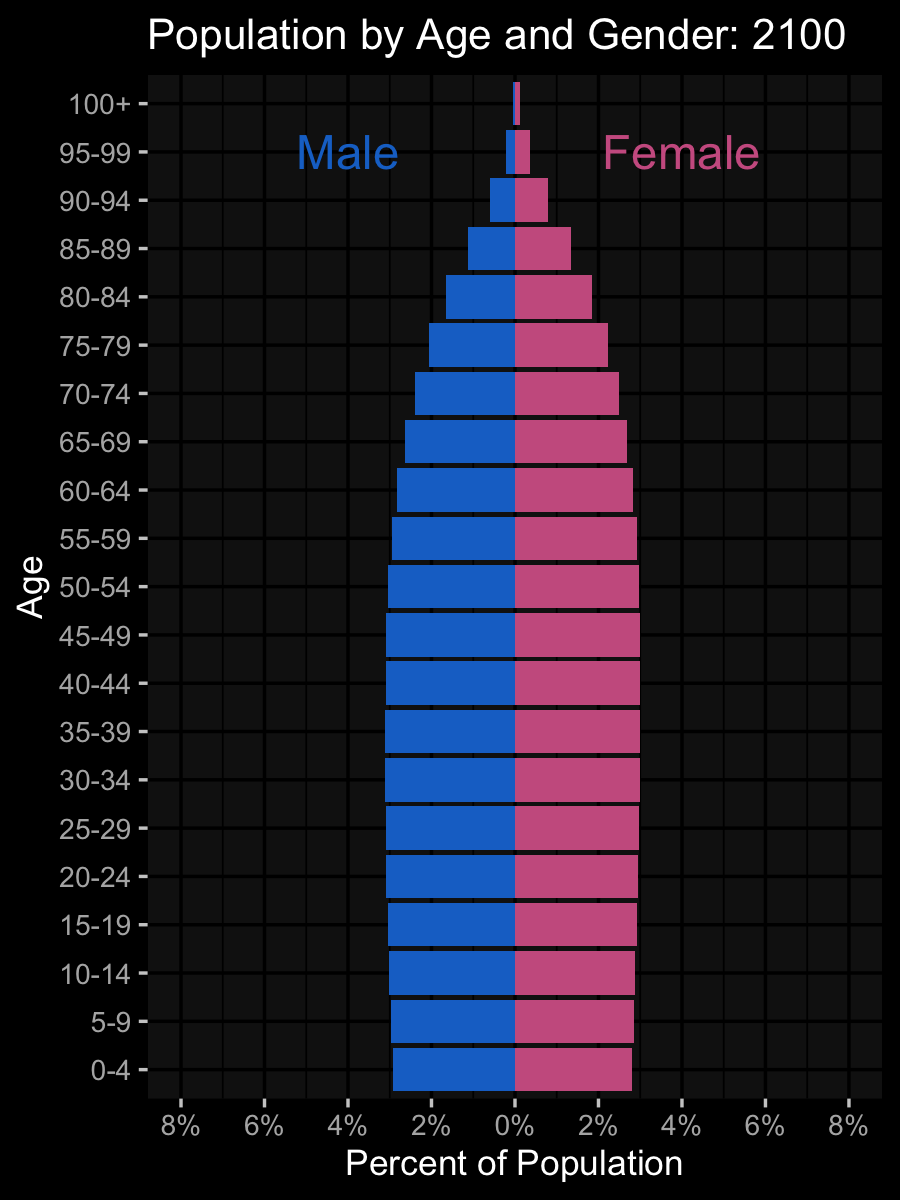
Error Detection

An analysis by Nuijten et al. (2016) of over 250K p-values reported in 8 major psych journals from 1985 to 2013 found that:
- half the papers had at least one inconsistent p-value
- 1/8 of papers had errors that could affect conclusions
- errors more likely to be erroneously significant than not
Code Reproducibility
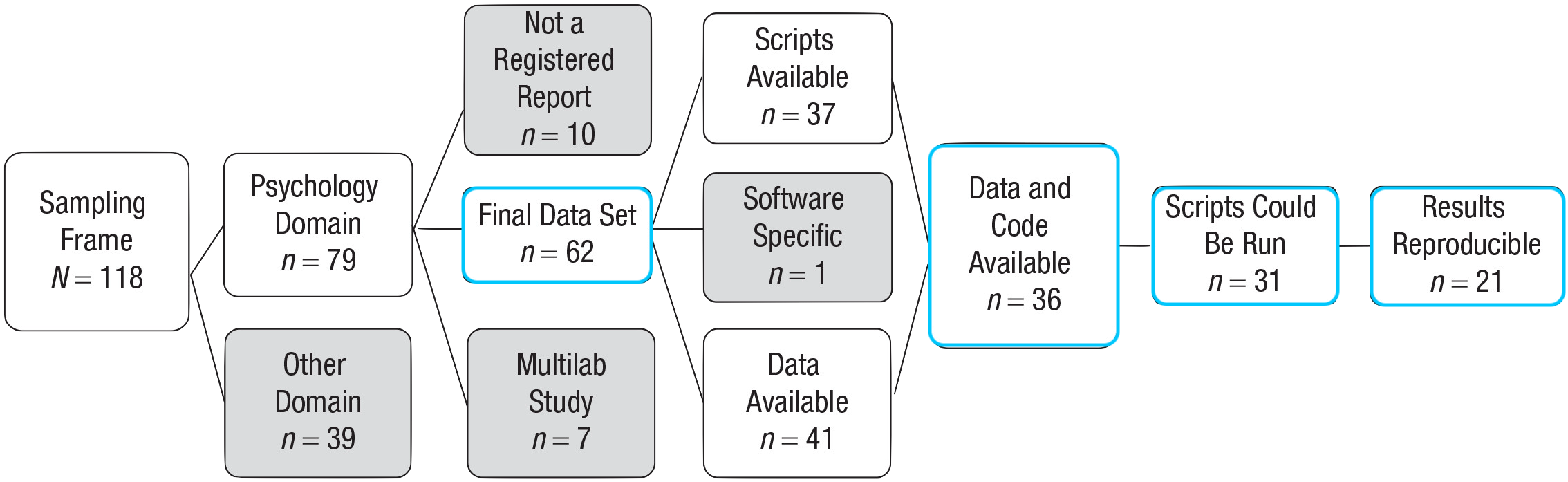
Of 62 Registered Reports in psychology published from 2014–2018, 36 had data and analysis code, 31 could be run, and 21 reproduced all the main results (Obels et al, 2020)
Barriers to Doing Code Review
Technical
- Lack of skill
- No guide
Incentive
- No time
- Not expected
Social
- Expectations
- Fear of judgement

Not Goals
- Debugging
- Code help
- Statistical help

Code Review Guide
Huge thanks to the Code Review Guide Team (especially Hao Ye, Kaija Gahm, Andrew Stewart, Elaine Kearney, Ekaterina Pronizius, Saeed Shafiei Sabet, Clare Conry Murray)
Anyone is welcome to get involved in the project.

Pre-Registration
Prep analysis scripts for pre-registration
Power
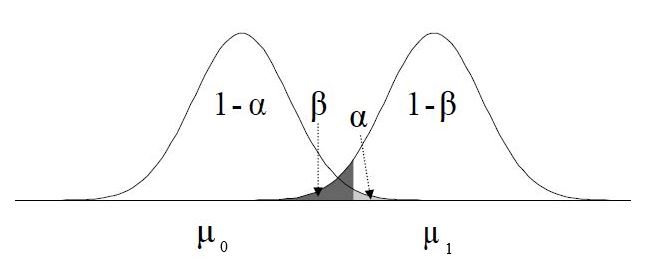
Calculate power and sensitivity for analyses that don’t have empirical methods
Reproducible Examples

Create reproducible examples when your data are too big or confidential to share
Enhance Understanding
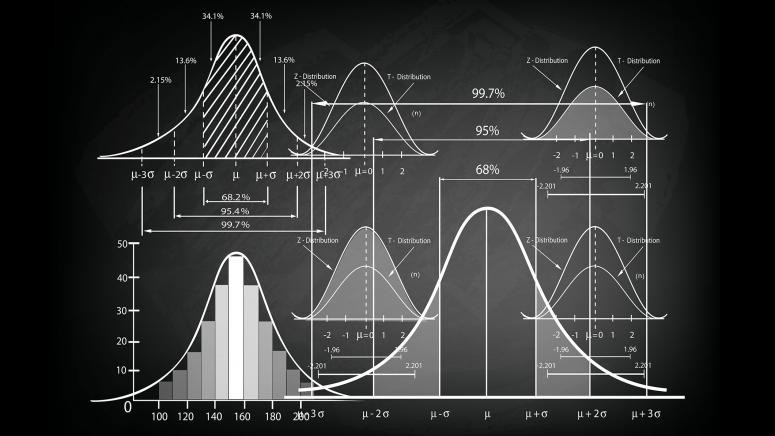
Enhance your understanding of statistical concepts
Teaching Data
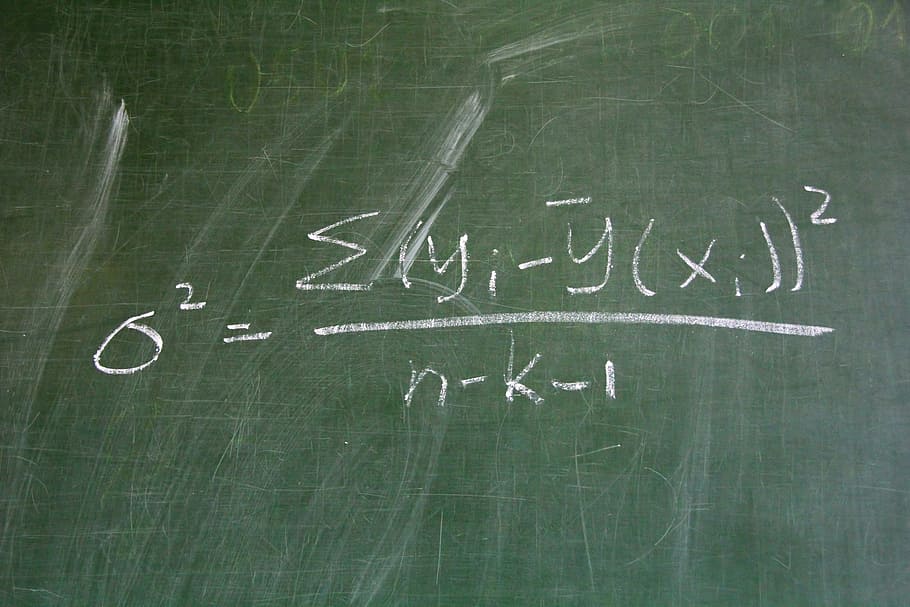
Create demo data for teaching and tutorials
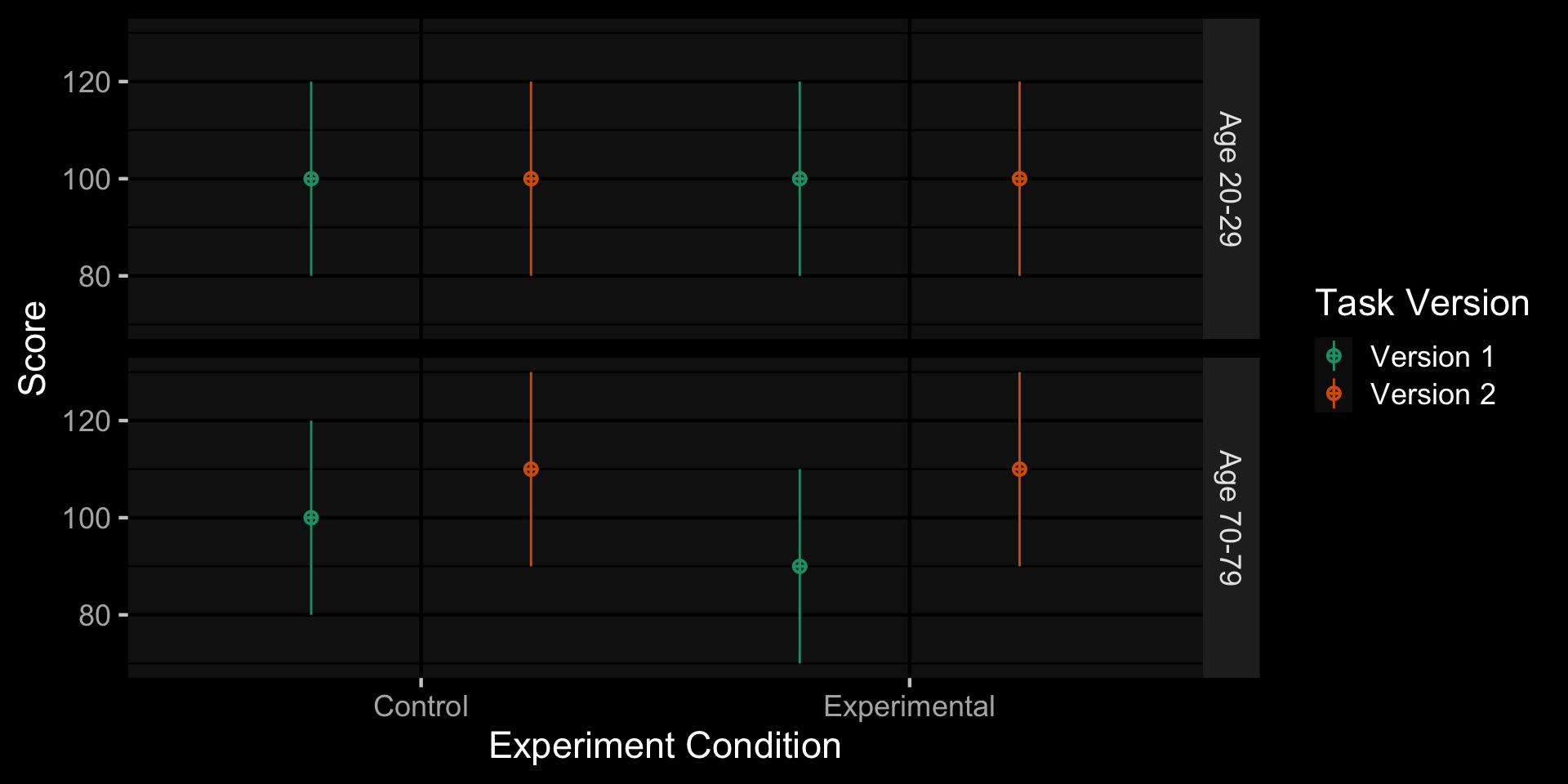
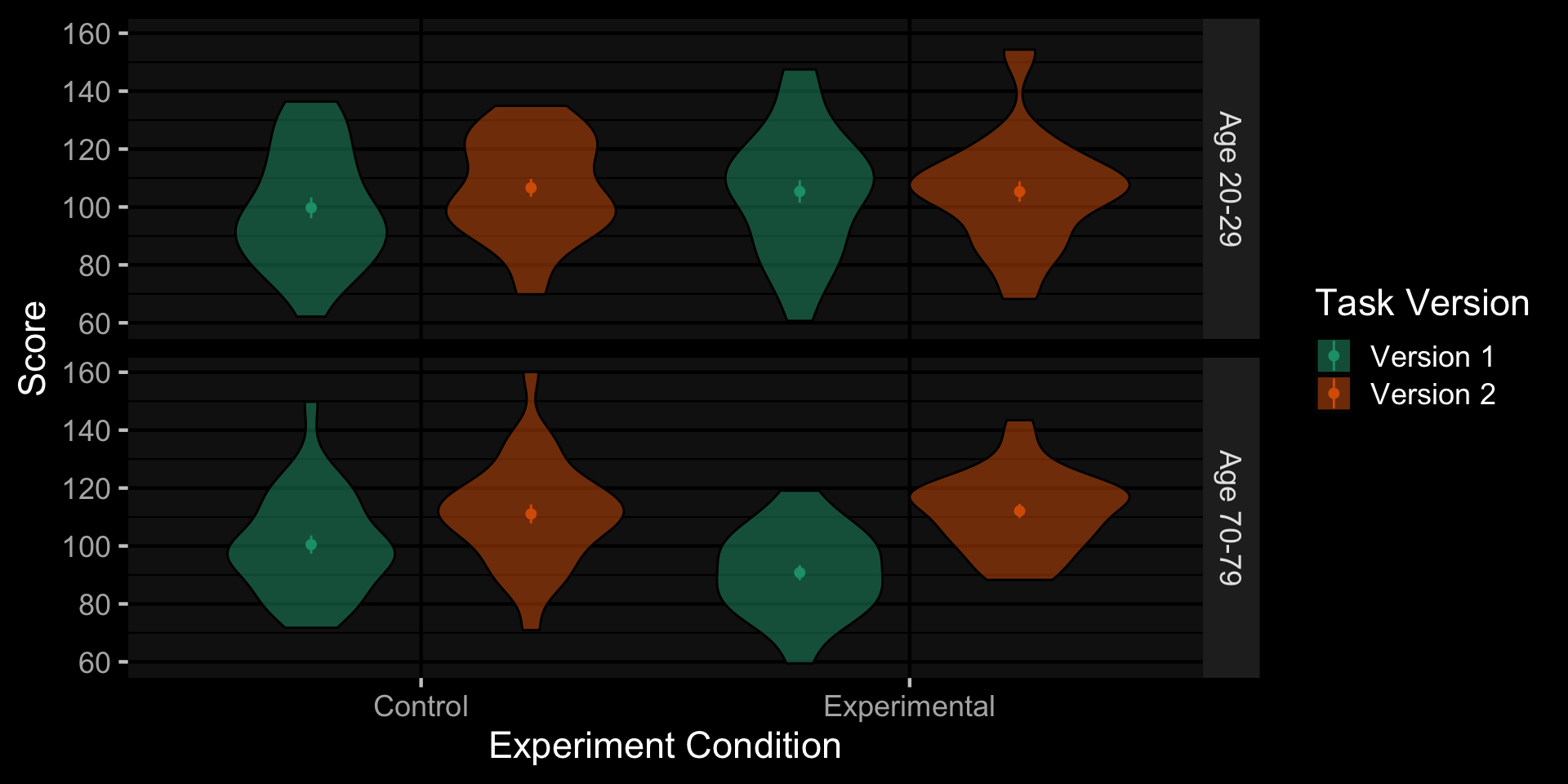
Faux (tinyurl.com/faux-app)
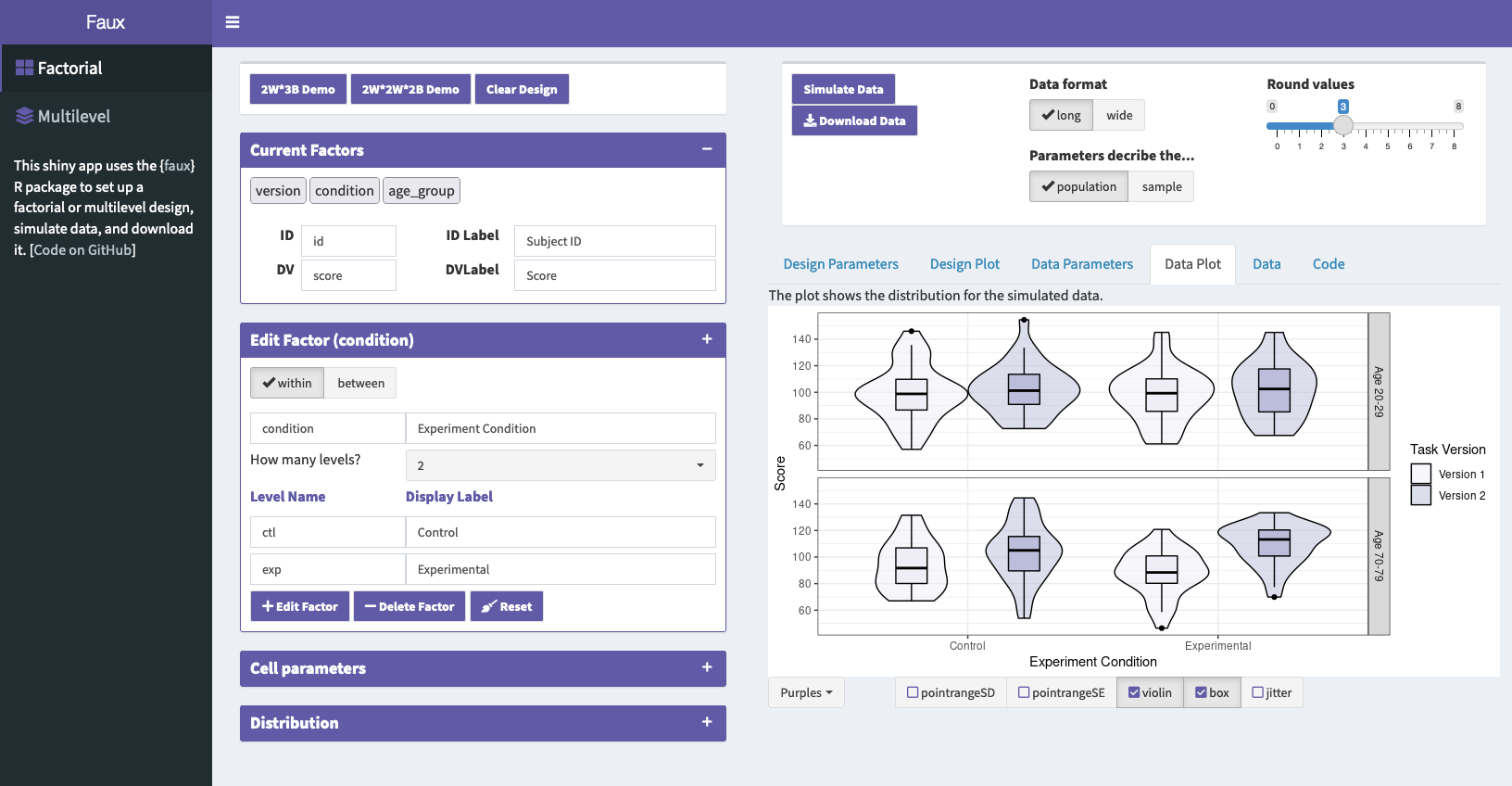
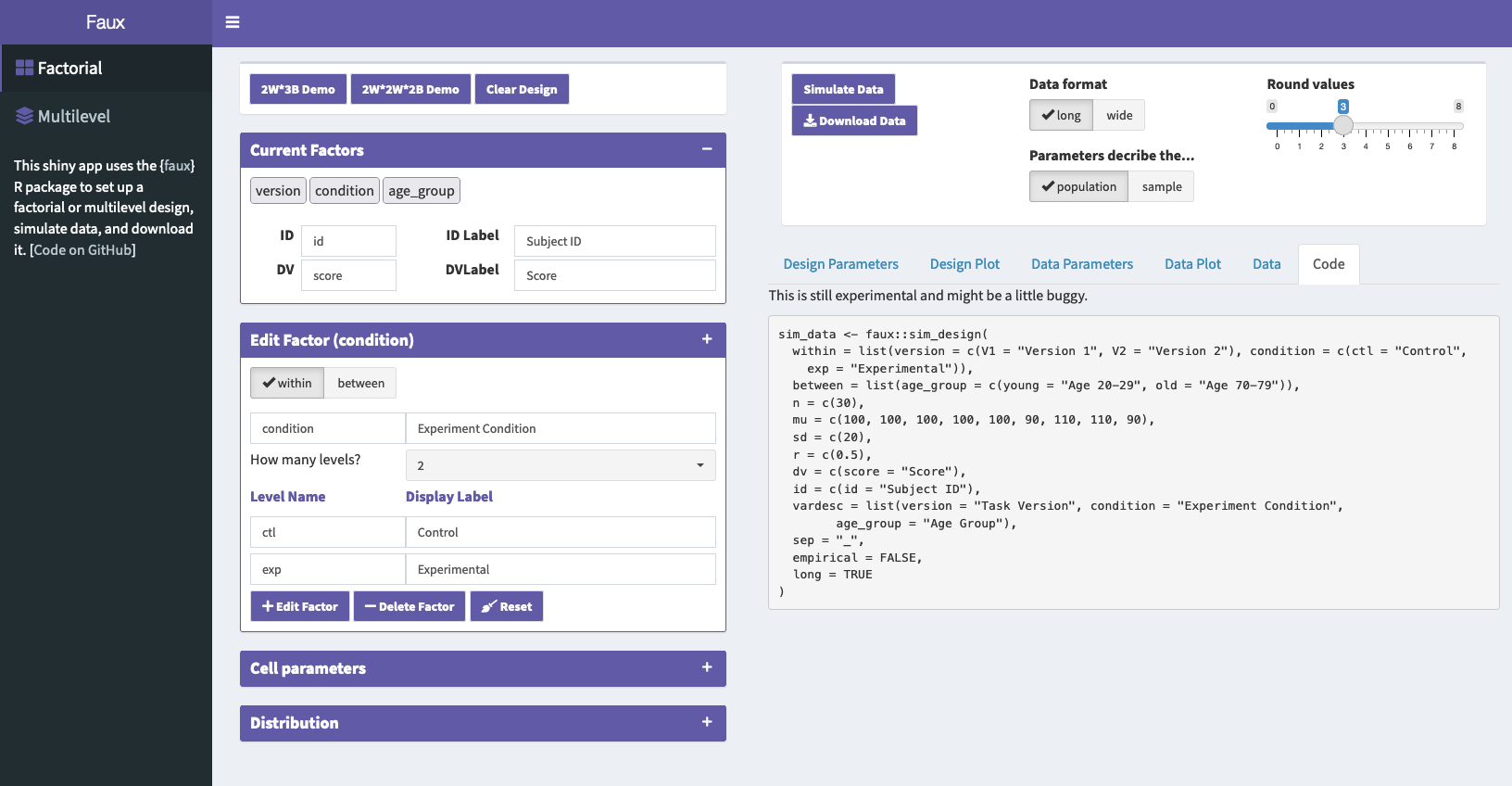
Faux Design Plot
Faux Data Plot
Further Resources


Thank You!
debruine.github.io/talks/CompCogSci-2023/ (code)
