Chapter 6 Data Relations

6.1 Learning Objectives
6.2 Resources
6.4 Data
First, we’ll create two small data tables.
subject has id, gender and age for subjects 1-5. Age and gender are missing for subject 3.
| id | gender | age |
|---|---|---|
| 1 | m | 19 |
| 2 | m | 22 |
| 3 | NA | NA |
| 4 | nb | 19 |
| 5 | f | 18 |
exp has subject id and the score from an experiment. Some subjects are missing, some completed twice, and some are not in the subject table.
| id | score |
|---|---|
| 2 | 10 |
| 3 | 18 |
| 4 | 21 |
| 4 | 23 |
| 5 | 9 |
| 5 | 11 |
| 6 | 11 |
| 6 | 12 |
| 7 | 3 |
6.5 Mutating Joins
Mutating joins act like the mutate() function in that they add new columns to one table based on values in another table.
All the mutating joins have this basic syntax:
****_join(x, y, by = NULL, suffix = c(".x", ".y")
x= the first (left) tabley= the second (right) tableby= what columns to match on. If you leave this blank, it will match on all columns with the same names in the two tables.suffix= if columns have the same name in the two tables, but you aren’t joining by them, they get a suffix to make them unambiguous. This defaults to “.x” and “.y”, but you can change it to something more meaningful.
You can leave out the by argument if you’re matching on all of the columns with the same name, but it’s good practice to always specify it so your code is robust to changes in the loaded data.
6.5.1 left_join()
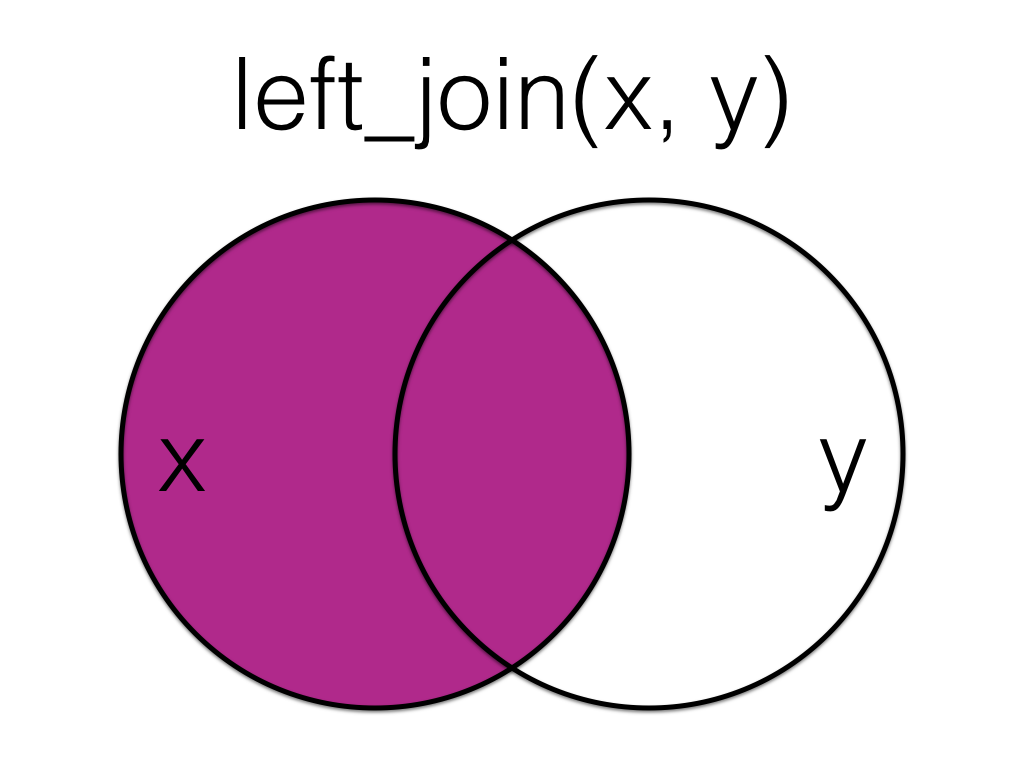
Figure 6.1: Left Join
A left_join keeps all the data from the first (left) table and joins anything that matches from the second (right) table. If the right table has more than one match for a row in the right table, there will be more than one row in the joined table (see ids 4 and 5).
## # A tibble: 7 x 4
## id gender age score
## <dbl> <chr> <dbl> <dbl>
## 1 1 m 19 NA
## 2 2 m 22 10
## 3 3 <NA> NA 18
## 4 4 nb 19 21
## 5 4 nb 19 23
## 6 5 f 18 9
## 7 5 f 18 11
Figure 6.2: Left Join (reversed)
The order of tables is swapped here, so the result is all rows from the exp table joined to any matching rows from the subject table.
## # A tibble: 9 x 4
## id score gender age
## <dbl> <dbl> <chr> <dbl>
## 1 2 10 m 22
## 2 3 18 <NA> NA
## 3 4 21 nb 19
## 4 4 23 nb 19
## 5 5 9 f 18
## 6 5 11 f 18
## 7 6 11 <NA> NA
## 8 6 12 <NA> NA
## 9 7 3 <NA> NA6.5.2 right_join()
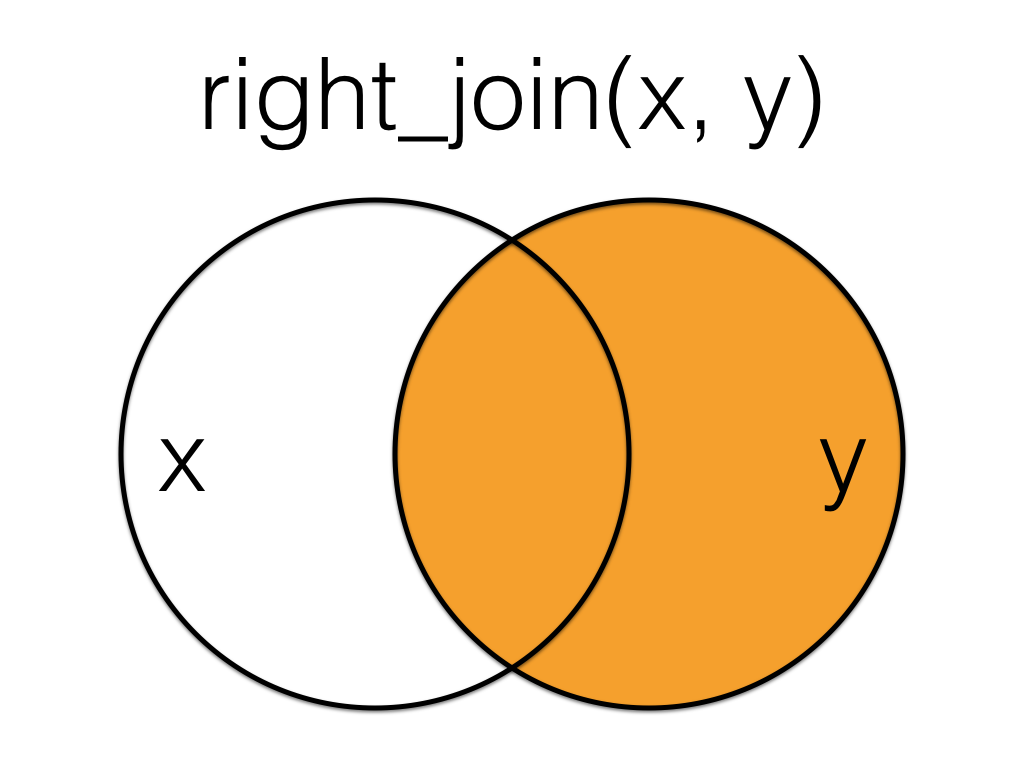
Figure 6.3: Right Join
A right_join keeps all the data from the second (right) table and joins anything that matches from the first (left) table.
## # A tibble: 9 x 4
## id gender age score
## <dbl> <chr> <dbl> <dbl>
## 1 2 m 22 10
## 2 3 <NA> NA 18
## 3 4 nb 19 21
## 4 4 nb 19 23
## 5 5 f 18 9
## 6 5 f 18 11
## 7 6 <NA> NA 11
## 8 6 <NA> NA 12
## 9 7 <NA> NA 3This table has the same information as left_join(exp, subject, by = "id"), but the columns are in a different order (left table, then right table).
6.5.3 inner_join()
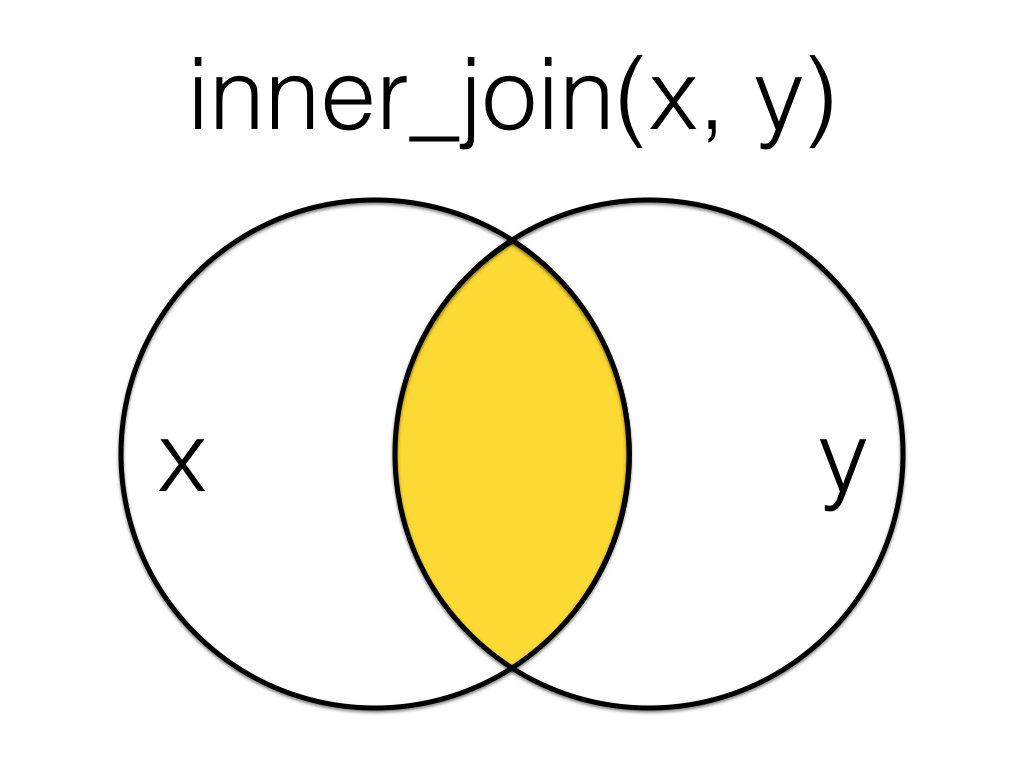
Figure 6.4: Inner Join
An inner_join returns all the rows that have a match in the other table.
## # A tibble: 6 x 4
## id gender age score
## <dbl> <chr> <dbl> <dbl>
## 1 2 m 22 10
## 2 3 <NA> NA 18
## 3 4 nb 19 21
## 4 4 nb 19 23
## 5 5 f 18 9
## 6 5 f 18 116.5.4 full_join()
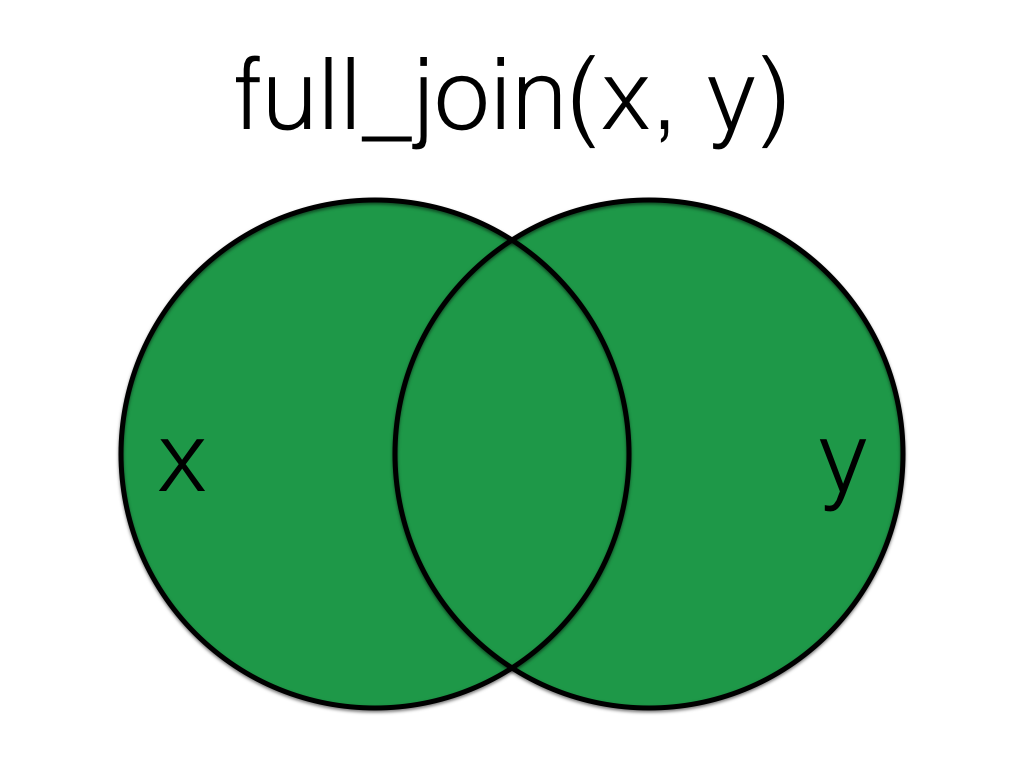
Figure 6.5: Full Join
A full_join lets you join up rows in two tables while keeping all of the information from both tables. If a row doesn’t have a match in the other table, the other table’s column values are set to NA.
## # A tibble: 10 x 4
## id gender age score
## <dbl> <chr> <dbl> <dbl>
## 1 1 m 19 NA
## 2 2 m 22 10
## 3 3 <NA> NA 18
## 4 4 nb 19 21
## 5 4 nb 19 23
## 6 5 f 18 9
## 7 5 f 18 11
## 8 6 <NA> NA 11
## 9 6 <NA> NA 12
## 10 7 <NA> NA 36.6 Filtering Joins
Filtering joins act like the filter() function in that they remove rows from the data in one table based on the values in another table. The result of a filtering join will only contain rows from the left table and have the same number or fewer rows than the left table.
6.6.1 semi_join()

Figure 6.6: Semi Join
A semi_join returns all rows from the left table where there are matching values in the right table, keeping just columns from the left table.
## # A tibble: 4 x 3
## id gender age
## <int> <chr> <dbl>
## 1 2 m 22
## 2 3 <NA> NA
## 3 4 nb 19
## 4 5 f 18Unlike an inner join, a semi join will never duplicate the rows in the left table if there is more than one matching row in the right table.

Figure 6.7: Semi Join (Reversed)
Order matters in a semi join.
## # A tibble: 6 x 2
## id score
## <dbl> <dbl>
## 1 2 10
## 2 3 18
## 3 4 21
## 4 4 23
## 5 5 9
## 6 5 116.6.2 anti_join()

Figure 6.8: Anti Join
An anti_join return all rows from the left table where there are not matching values in the right table, keeping just columns from the left table.
## # A tibble: 1 x 3
## id gender age
## <int> <chr> <dbl>
## 1 1 m 19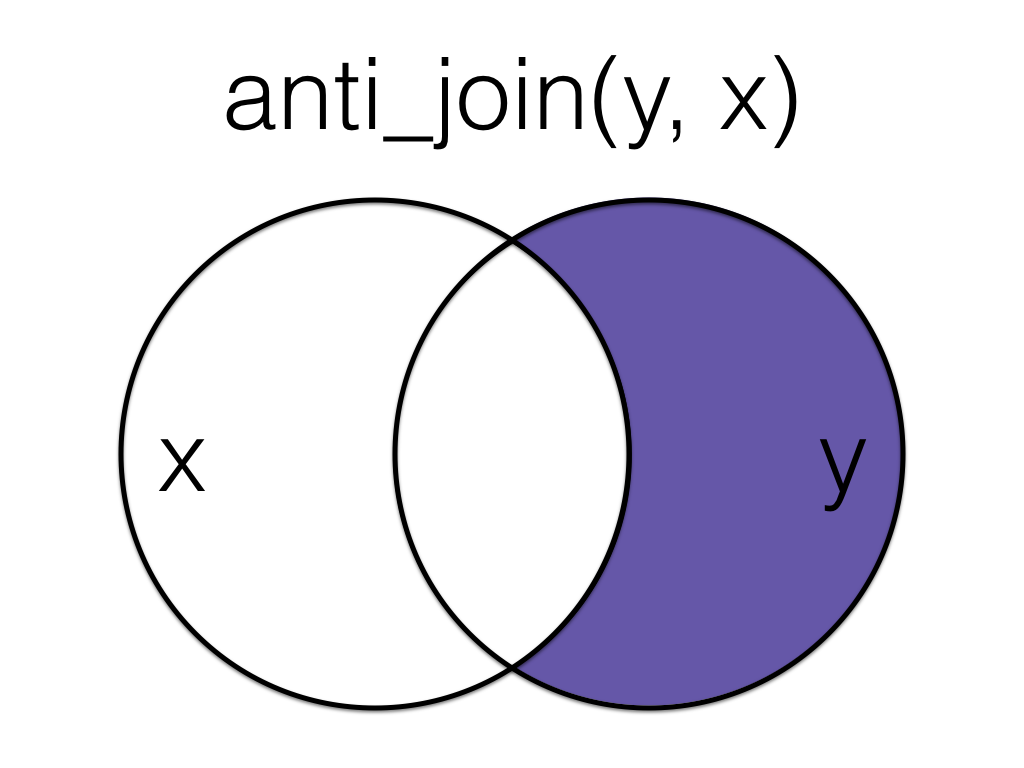
Figure 6.9: Anti Join (Reversed)
Order matters in an anti join.
## # A tibble: 3 x 2
## id score
## <dbl> <dbl>
## 1 6 11
## 2 6 12
## 3 7 36.7 Binding Joins
Binding joins bind one table to another by adding their rows or columns together.
6.7.1 bind_rows()
You can combine the rows of two tables with bind_rows.
Here we’ll add subject data for subjects 6-9 and bind that to the original subject table.
new_subjects <- tibble(
id = 6:9,
gender = c("nb", "m", "f", "f"),
age = c(19, 16, 20, 19)
)
bind_rows(subject, new_subjects)## # A tibble: 9 x 3
## id gender age
## <int> <chr> <dbl>
## 1 1 m 19
## 2 2 m 22
## 3 3 <NA> NA
## 4 4 nb 19
## 5 5 f 18
## 6 6 nb 19
## 7 7 m 16
## 8 8 f 20
## 9 9 f 19The columns just have to have the same names, they don’t have to be in the same order. Any columns that differ between the two tables will just have NA values for entries from the other table.
If a row is duplicated between the two tables (like id 5 below), the row will also be duplicated in the resulting table. If your tables have the exact same columns, you can use union() (see below) to avoid duplicates.
new_subjects <- tibble(
id = 5:9,
age = c(18, 19, 16, 20, 19),
gender = c("f", "nb", "m", "f", "f"),
new = c(1,2,3,4,5)
)
bind_rows(subject, new_subjects)## # A tibble: 10 x 4
## id gender age new
## <int> <chr> <dbl> <dbl>
## 1 1 m 19 NA
## 2 2 m 22 NA
## 3 3 <NA> NA NA
## 4 4 nb 19 NA
## 5 5 f 18 NA
## 6 5 f 18 1
## 7 6 nb 19 2
## 8 7 m 16 3
## 9 8 f 20 4
## 10 9 f 19 56.7.2 bind_cols()
You can merge two tables with the same number of rows using bind_cols. This is only useful if the two tables have their rows in the exact same order. The only advantage over a left join is when the tables don’t have any IDs to join by and you have to rely solely on their order.
new_info <- tibble(
colour = c("red", "orange", "yellow", "green", "blue")
)
bind_cols(subject, new_info)## # A tibble: 5 x 4
## id gender age colour
## <int> <chr> <dbl> <chr>
## 1 1 m 19 red
## 2 2 m 22 orange
## 3 3 <NA> NA yellow
## 4 4 nb 19 green
## 5 5 f 18 blue6.8 Set Operations
Set operations compare two tables and return rows that match (intersect), are in either table (union), or are in one table but not the other (setdiff).
6.8.1 intersect()
intersect() returns all rows in two tables that match exactly. The columns don’t have to be in the same order.
new_subjects <- tibble(
id = seq(4, 9),
age = c(19, 18, 19, 16, 20, 19),
gender = c("f", "f", "m", "m", "f", "f")
)
intersect(subject, new_subjects)## # A tibble: 1 x 3
## id gender age
## <int> <chr> <dbl>
## 1 5 f 18If you’ve forgotten to load dplyr or the tidyverse, base R also has an intersect() function. The error message can be confusing and looks something like this:
## Error: Must subset rows with a valid subscript vector.
## [34mℹ[39m Logical subscripts must match the size of the indexed input.
## [31mx[39m Input has size 6 but subscript `!duplicated(x, fromLast = fromLast, ...)` has size 0.6.8.2 union()
union() returns all the rows from both tables, removing duplicate rows.
## # A tibble: 10 x 3
## id gender age
## <int> <chr> <dbl>
## 1 1 m 19
## 2 2 m 22
## 3 3 <NA> NA
## 4 4 nb 19
## 5 5 f 18
## 6 4 f 19
## 7 6 m 19
## 8 7 m 16
## 9 8 f 20
## 10 9 f 19If you’ve forgotten to load dplyr or the tidyverse, base R also has a union() function. You usually won’t get an error message, but the output won’t be what you expect.
## [[1]]
## [1] 1 2 3 4 5
##
## [[2]]
## [1] "m" "m" NA "nb" "f"
##
## [[3]]
## [1] 19 22 NA 19 18
##
## [[4]]
## [1] 4 5 6 7 8 9
##
## [[5]]
## [1] 19 18 19 16 20 19
##
## [[6]]
## [1] "f" "f" "m" "m" "f" "f"6.8.3 setdiff()
setdiff returns rows that are in the first table, but not in the second table.
## # A tibble: 4 x 3
## id gender age
## <int> <chr> <dbl>
## 1 1 m 19
## 2 2 m 22
## 3 3 <NA> NA
## 4 4 nb 19Order matters for setdiff.
## # A tibble: 5 x 3
## id age gender
## <int> <dbl> <chr>
## 1 4 19 f
## 2 6 19 m
## 3 7 16 m
## 4 8 20 f
## 5 9 19 fIf you’ve forgotten to load dplyr or the tidyverse, base R also has a setdiff() function. You usually won’t get an error message, but the output might not be what you expect because the base R setdiff() expects columns to be in the same order, so id 5 here registers as different between the two tables.
## # A tibble: 5 x 3
## id gender age
## <int> <chr> <dbl>
## 1 1 m 19
## 2 2 m 22
## 3 3 <NA> NA
## 4 4 nb 19
## 5 5 f 186.9 Glossary
| term | definition |
|---|---|
| base r | The set of R functions that come with a basic installation of R, before you add external packages |
| binding joins | Joins that bind one table to another by adding their rows or columns together. |
| filtering joins | Joins that act like the dplyr::filter() function in that they remove rows from the data in one table based on the values in another table. The result of a filtering join will only contain rows from the left table and have the same number or fewer rows than the left table. |
| mutating joins | Joins that act like the dplyr::mutate() function in that they add new columns to one table based on values in another table. |
| set operations | Functions that compare two tables and return rows that match (intersect), are in either table (union), or are in one table but not the other (setdiff). |