Multi-Row Headers
A student on our help forum recently asked for help making a wide-format dataset long. When I tried to load the data, I realised the first three rows were all header rows. Here’s the code I wrote to deal with it.
First, I’ll make a small CSV “file” below. In a typical case, you’d read the data in from a file.
demo_csv <- "SUB1, SUB1, SUB1, SUB1, SUB2, SUB2, SUB2, SUB2
COND1, COND1, COND2, COND2, COND1, COND1, COND2, COND2
X, Y, X, Y, X, Y, X, Y
10, 15, 6, 2, 42, 4, 32, 5
4, 43, 7, 34, 56, 43, 2, 33
77, 12, 14, 75, 36, 85, 3, 2"If you try to read in this data, you’ll get an error message about the duplicate column names.
data <- read_csv(demo_csv)## Warning: Duplicated column names deduplicated: 'SUB1' => 'SUB1_1' [2], 'SUB1'
## => 'SUB1_2' [3], 'SUB1' => 'SUB1_3' [4], 'SUB2' => 'SUB2_1' [6], 'SUB2' =>
## 'SUB2_2' [7], 'SUB2' => 'SUB2_3' [8]Instead, you should read in just the header rows by setting n_max equal to the number of header rows and col_names to FALSE.
data_head <- read_csv(demo_csv, n_max = 3, col_names = FALSE)You will get a table that looks like this:
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 |
|---|---|---|---|---|---|---|---|
| SUB1 | SUB1 | SUB1 | SUB1 | SUB2 | SUB2 | SUB2 | SUB2 |
| COND1 | COND1 | COND2 | COND2 | COND1 | COND1 | COND2 | COND2 |
| X | Y | X | Y | X | Y | X | Y |
You can then transpose the table (rotate it) and make new header names by pasting together the names of the three headers.
new_names <- data_head %>%
t() %>% # transposes the data and turns it into a matrix
as_tibble() %>% # turn it back to a tibble
mutate(name = paste(V1, V2, V3, sep = "_")) %>%
pull(name)## Warning: The `x` argument of `as_tibble.matrix()` must have unique column names if `.name_repair` is omitted as of tibble 2.0.0.
## Using compatibility `.name_repair`.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.Now you can read in the data without the three header rows. Use skip to skip the headers and set col_names to the new names.
data <- read_csv(demo_csv, skip = 3, col_names = new_names)If you have an excel file that merges the duplicate headers across rows, it’s a little trickier, but still do-able.
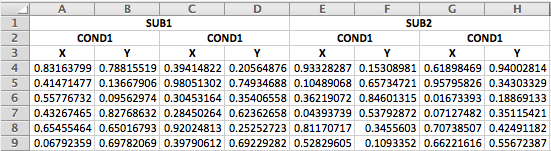
The first steps is the same: read in the first three rows.
data_head <- readxl::read_excel("3headers_demo.xlsx", n_max = 3, col_names = FALSE)## New names:
## * `` -> ...1
## * `` -> ...2
## * `` -> ...3
## * `` -> ...4
## * `` -> ...5
## * ...| …1 | …2 | …3 | …4 | …5 | …6 | …7 | …8 |
|---|---|---|---|---|---|---|---|
| SUB1 | NA | NA | NA | SUB2 | NA | NA | NA |
| COND1 | NA | COND2 | NA | COND1 | NA | COND2 | NA |
| X | Y | X | Y | X | Y | X | Y |
The function below starts at the top and fills in any missing data with the value in the previous row. You’ll have to define this function in your script before you run the next part.
fillHeaders <- function(header_table) {
for (row in 2:nrow(header_table)) {
this_row <- header_table[row, ]
last_row <- header_table[row-1, ]
new_row <- ifelse(is.na(this_row), last_row, this_row)
header_table[row, ] <- new_row
}
header_table
}Just run the fillHeaders() function after you transpose as re-tibble the header data, then continue generating the pasted name the same as above.
new_names <- data_head %>%
t() %>% # transposes the data and turns it into a matrix
as_tibble() %>% # turn it back to a tibble
fillHeaders() %>% # fill in missing headers
mutate(name = paste(V1, V2, V3, sep = "_")) %>%
pull(name)If your data are set up with multiple headers, you’ll probably want to change them from wide to long format. Here’s a quick example how to use gather, separate, and spread to do this with variable names like above.
data <- readxl::read_excel("3headers_demo.xlsx", skip = 3, col_names = new_names)
data_long <- data %>%
# add row IDs if each row doesn't already have uniquely identifying column(s)
mutate(trial = row_number()) %>%
# gather creates a column of variable names and a column of values
gather("var", "val", new_names) %>%
# split the variable names into their three component parts
separate(var, c("subID", "condition", "coord"), sep = "_") %>%
# put X and Y in separate columns
spread(coord, val)## Note: Using an external vector in selections is ambiguous.
## ℹ Use `all_of(new_names)` instead of `new_names` to silence this message.
## ℹ See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
## This message is displayed once per session.| trial | subID | condition | X | Y |
|---|---|---|---|---|
| 1 | SUB1 | COND1 | 0.8316380 | 0.7881552 |
| 1 | SUB1 | COND2 | 0.3941482 | 0.2056488 |
| 1 | SUB2 | COND1 | 0.9332829 | 0.1530898 |
| 1 | SUB2 | COND2 | 0.6189847 | 0.9400281 |
| 2 | SUB1 | COND1 | 0.4147148 | 0.1366791 |
| 2 | SUB1 | COND2 | 0.9805130 | 0.7493469 |
| 2 | SUB2 | COND1 | 0.1048907 | 0.6573472 |
| 2 | SUB2 | COND2 | 0.9579583 | 0.3430333 |
| 3 | SUB1 | COND1 | 0.5577673 | 0.0956297 |
| 3 | SUB1 | COND2 | 0.3045316 | 0.3540656 |
| 3 | SUB2 | COND1 | 0.3621907 | 0.8460132 |
| 3 | SUB2 | COND2 | 0.0167339 | 0.1886913 |
| 4 | SUB1 | COND1 | 0.4326746 | 0.8276863 |
| 4 | SUB1 | COND2 | 0.2845026 | 0.6236266 |
| 4 | SUB2 | COND1 | 0.0439374 | 0.5379287 |
| 4 | SUB2 | COND2 | 0.0712748 | 0.3511542 |
| 5 | SUB1 | COND1 | 0.6545546 | 0.6501679 |
| 5 | SUB1 | COND2 | 0.9202481 | 0.2525272 |
| 5 | SUB2 | COND1 | 0.8117072 | 0.3455603 |
| 5 | SUB2 | COND2 | 0.7073851 | 0.4249118 |
| 6 | SUB1 | COND1 | 0.0679236 | 0.6978207 |
| 6 | SUB1 | COND2 | 0.3979061 | 0.6922928 |
| 6 | SUB2 | COND1 | 0.5282960 | 0.1093352 |
| 6 | SUB2 | COND2 | 0.6622162 | 0.5567239 |
Lisa DeBruine
Professor of Psychology
Lisa DeBruine is a professor of psychology at the University of Glasgow. Her substantive research is on the social perception of faces and kinship. Her meta-science interests include team science (especially the Psychological Science Accelerator), open documentation, data simulation, web-based tools for data collection and stimulus generation, and teaching computational reproducibility.