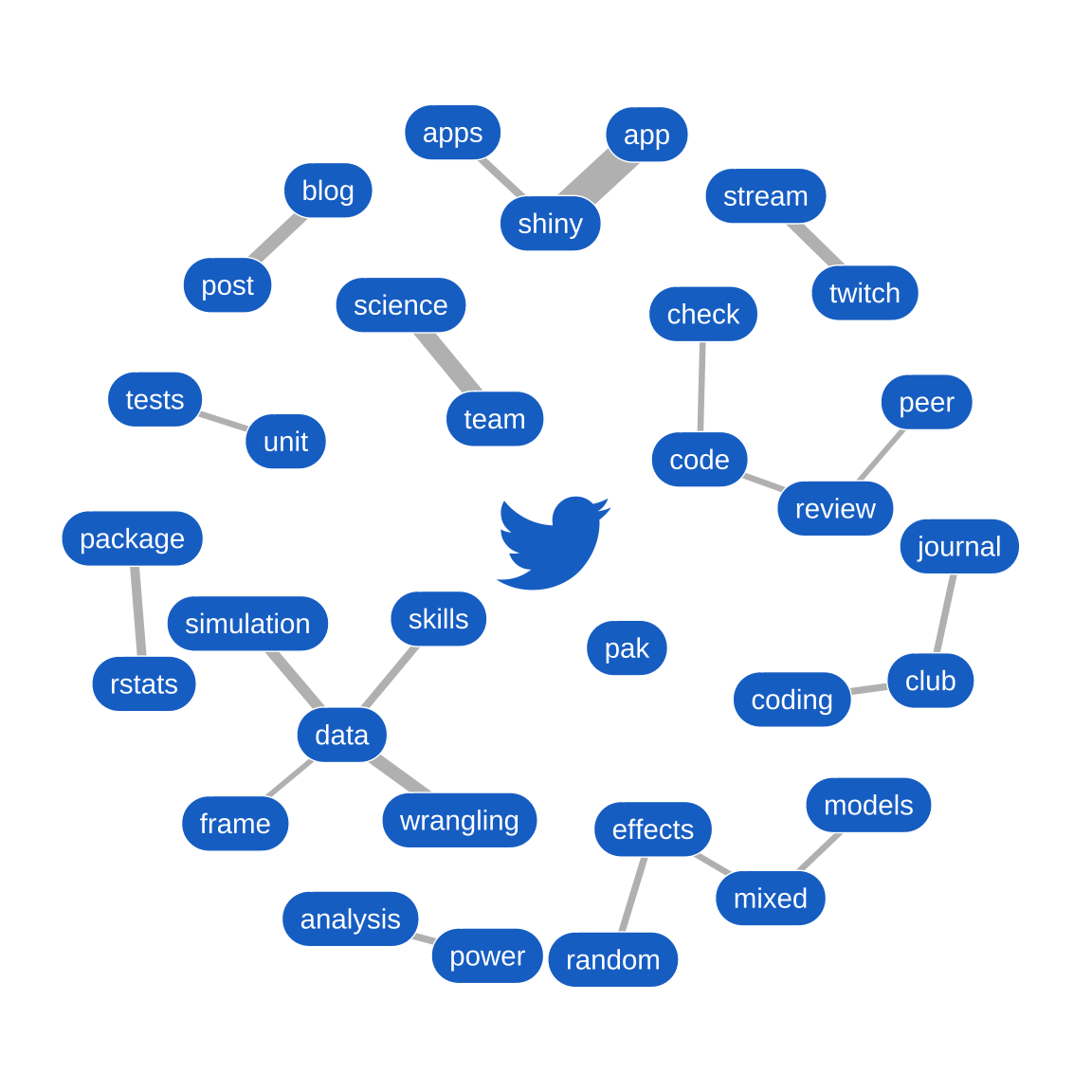
I’ve been meaning to learn more about visualising text, and where better to start than Julia Silge and David Robinson’s Text Mining with R!
Setup
library(tidyverse) # always usefullibrary(tidytext) # for text analysislibrary(ggraph) # for plotting ngramslibrary(showtext) # for custom fontslibrary(ggtext) # for adding the twitter logofont_add("arista", "fonts/arista_light.ttf")font_add("fa-brands", "fonts/fa-brands-400.ttf")showtext_auto()
Here I used the code from the ngrams chapter to get a table of all the word pairs in my tweets. I added one line to get rid of all the twitter usernames (i.e., any word that starts with @).
The most common ones are stop words, so separate the words into word1 and word2 and get rid of any rows without words (e.g., 1-word tweets). I added a few custom entries to the stop_words$words list: “https”, “t.co”, “gt”, “lt”, and the numbers 0 to 100.